 Image credit: KineBench authors
Image credit: KineBench authorsAbstract
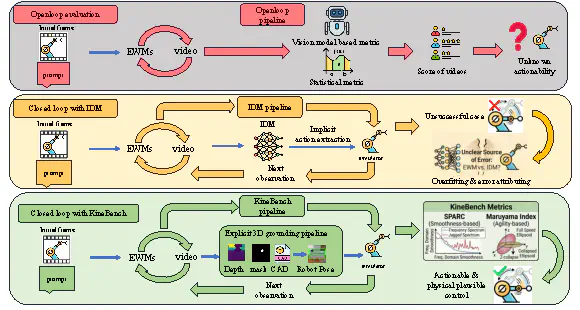
Evaluating the physical consistency of embodied world models (EWMs) is a critical open challenge. While closed-loop evaluation via simulator rollouts offers a more faithful assessment of physical plausibility than open-loop alternatives, existing frameworks almost exclusively rely on Inverse Dynamics Models (IDMs) for action extraction. Due to the intricate mapping from 2D pixel space to 3D kinematic space, the learned IDMs can be brittle to data outside their training distribution, resulting in unreliable action extraction from the generated videos with novel objects and scenarios. This creates an unavoidable attribution ambiguity between world model inaccuracies and extractor errors. To eliminate this ambiguity, we present KineBench, the first IDM-free closed-loop benchmark for EWMs, built upon an explicit kinematic grounding pipeline. Given a generated video, KineBench employs cascaded visual foundation models to directly extract 6D end-effector poses from individual frames, which are then executed in a physics simulator for closed-loop validation. This explicit grounding directly tests the physical feasibility rather than visual plausibility, while remaining sensitive to general physical hallucinations such as gripper vanishing or spatial inconsistency. Beyond execution-based task success assessment, KineBench introduces two 3D kinematic metrics, Spectral Arc Length (SPARC) and the Maruyama Manipulability Index, to evaluate trajectory smoothness and kinematic dexterity from a robot-centric perspective. We empirically demonstrate a strong correlation between these metrics and physical success rate, establishing them as reliable proxies for embodied generation quality. Built on 20 diverse manipulation tasks in ManiSkill3, KineBench evaluates EWMs across four progressive suites, including basic execution, task transfer, visual out-of-distribution generalization, and complexity-conditioned scaling. Extensive evaluation of frontier models reveals a non-linear scaling behavior in embodied video generation bounded by task complexity, offering rigorous empirical guidance for future data scaling strategies.